Hand Gesture Recognition Assisted by Human Pose Information
Eun Mi Park, In Su Kim and Soon Ki Jung
School of Computer Science and Engineering, Kyungpook National University
80 Daehakro, Buk-gu
Daegu, Republic of Korea
coil2002@vr.knu.ac.kr, iskim69@vr.knu.ac.kr, skjung@knu.ac.kr
Abstract
This paper proposes a monocular camera based hand gesture recognition system assisted by human pose information. The system consists of two modules. At first, we extract the human pose information with PoseNet [5] and the wrist joint information is refined by Kalman filtering. From the result, we obtain the ROI (region of interest) of hands, in which we robustly detect and track hands even for the variations in the background and illumination. Next, we classify hand gestures using the convolutional neural network (CNN). The hand gesture information assisted by the human pose information can be used for various applications. In order to demonstrate the usefulness of the system, we build a simple AR camera system in which several virtual objects are augmented on the human face according to the hand gestures.
Keywords-component; Monocular camera, hand gesture recognition, human pose estimation, CNN, virtual object augmentation
1. Introduction
As hardware and software advances, the importance of how a human interacts with a computer also increases [1]. In recent years, many studies have been conducted to provide a natural user interface through gesture recognition without using input devices. The visual interface involving gestures is one of the most familiar and convenient ways for human among various interface methods. Gesture recognition allows human to communicate with a smart device without touching the keyboard, mouse. Hands are suitable for the human-interaction interaction. Since they forma more sophisticated language system called sign language, which has more gesture patterns than other body parts. Thus, we propose a monocular camera based hand gesture recognition system assisted by human pose information. By using the pose information, our proposed system is robust to illumination, background change and allows rich interaction between a user and a computer.
2. Related work
Most hand gesture recognition systems perform background-foreground extraction primarily using RGB or RGBD cameras. The background-foreground segmentation based on the skin color is performed first to recognize the shape of a hand and then the gesture is recognized. Using the RGBD camera, it is possible to use the depth and skin color information together to find a hand in the scene. However, in an RGB camera environment, extracting the hand shape using the skin color is vulnerable to changes in illumination and background [2].With recent advances in the GPU technology, it is possible to use the CNN more accurately to classify the gestures [3][4]. CNN is an artificial neural network primarily used to classify the data such as images and videos. The numbers of hand gestures are limited because the range of fingers moving around a hand is limited. Therefore, our proposed system can recognize the hand gesture using a monocular camera by estimating the human pose. The PoseNet is widely used for estimating the pose which is a bottom-up camera-based model [5]. This model is trained using COCO (Common Objects in Context) keypoint dataset and learns about 17 different joints including eyes, nose, mouth, and ears. The learned information is returned as the output of the PoseNet model. Each joint information contains its position along with the confidence score. We used the wrist joint information to find the region of interest (ROI) of a hand and then the hand gesture is classified through a CNN. Later, we used shoulder joint information to precisely distinguish the gestures.
3. Implementation details
As shown in Fig.1, our proposed system has three main parts: 1) obtaining the wrist joint information, 2) fine-tuning for the hand gesture classification task, 3) augmenting the object.
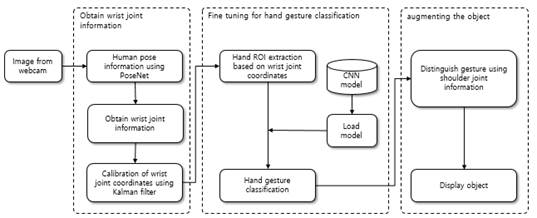
Fig.1 System architecture consisting of three main parts.
3.1. Obtaining the joint information
The system gets a 640![]() 480 pixels input color
image captured with a webcam. Then, Using the PoseNet, it estimates the posture
and obtains keypoint positions and a keypoint reliability scores for user's 17
joints. The keypoint position provides(x, y) coordinates which exist on a two-dimensional
plane of the joints. The keypoint reliability score determines the confidence to
make sure that the estimated keypoint position is accurate and ranges between
0.0 and 1.0.
480 pixels input color
image captured with a webcam. Then, Using the PoseNet, it estimates the posture
and obtains keypoint positions and a keypoint reliability scores for user's 17
joints. The keypoint position provides(x, y) coordinates which exist on a two-dimensional
plane of the joints. The keypoint reliability score determines the confidence to
make sure that the estimated keypoint position is accurate and ranges between
0.0 and 1.0.
When testing the system in a real environment, the PoseNet returns incorrect position which is different from the actual joint coordinates given the low confidence score for a joint's keypoint. Therefore, when the keypoint confidence score is lower than the default minimum confidence value of 0.15 (as set by the PoseNet), we improved the accuracy using the Kalman filter (KF) to calibrate the joint coordinate information. The gesture recognition rate is improved by the KF as it can be seen in section 4. System analysis.
3.2. Fine tuning for hand gesture classification
The system uses a CNN model
obtained by fine-tuning the existing model learned with ImageNet. Two patches,
each enclosing a hand, of size 180![]() 200 pixel is extracted
per frame using a calibrated wrist coordinate with KF. These extracted patches
form a dataset for training a CNN model. The classification of the input data
is shown in Fig.2. We used the ResNet-101 model pre-trained on the ImageNet for
fine tuning.
200 pixel is extracted
per frame using a calibrated wrist coordinate with KF. These extracted patches
form a dataset for training a CNN model. The classification of the input data
is shown in Fig.2. We used the ResNet-101 model pre-trained on the ImageNet for
fine tuning.

Fig.2 Three static hand gestures (names from left to right: Fist, Two, Five) for training.
3.3. Augmenting the object
The proposed system uses the joint information estimated from the PoseNet output. It can further distinguish the same gesture by comparing the position of a wrist with the position of a joint. The position is a coordinate existing on a two-dimensional plane. The comparison takes place in these two stages: 1)the system uses the wrist joint information value to decide whether there is a left or right hand,2)it finds the wrist position as above, middle or below the shoulder line. If the wrist position lies on the shoulder line, it is distinguished as ‘above’. The shoulder line means a line passing through the left and right shoulder joints. The system returns four different output values for each recognized hand gesture. Fig. 3 shows the system showing 12 different results using three hand gestures.

Fig.3 12 results using three classified hand gestures (names from top to bottom: Five, Two, Fist).
The system can also show several virtual objects since it has accurate joint information of a user. Fig. 4 shows the four different virtual objects when the system recognizes the 'Five' gesture.

Fig.4 The system recognizes four types of classified 'Five' gestures and then shows the virtual object (that are from left to right: cat ear, rabbit ear, heart, and glasses).
4. System analysis
We extracted the hand ROI using the wrist joint information. However, as mentioned in Section 3.1, the PoseNet may return wrong joint coordinates if the joint's keypoint confidence score is low. So, we used the KF to calibrate the wrist coordinates when the confidence score was less than 1.5. We further calculated the recognition rate to verify the improved accuracy for the hand recognition using the equation given as (1).
To calculate gesture
recognition rate, we assume the missing error and the classification error. The
missing error is used to count the occurrences when the hand was not detected
at all. It is because the hand ROI is not extracted properly due to the wrong
wrist coordinate value. The classification error denotes the inability of the
system to correctly recognize hand gesture. This could be because of improper CNN
classification using hand ROI. In Table 1,![]() is the total number
of frames with gesture in the input video,
is the total number
of frames with gesture in the input video, ![]() is the number of
correctly recognized frames,
is the number of
correctly recognized frames, ![]() is the number of missing
errors, and
is the number of missing
errors, and ![]() is the number of classification
errors, and
is the number of classification
errors, and ![]() is the accuracy of
gesture recognition. Also, '(K)' appended to the gesture name means that the KF
is used. As shown in Table 1, using KF reduces the missing error and increases
the recognition rate for the given gestures.
is the accuracy of
gesture recognition. Also, '(K)' appended to the gesture name means that the KF
is used. As shown in Table 1, using KF reduces the missing error and increases
the recognition rate for the given gestures.
![]() (1)
(1)
Table 1. Hand gesture recognition accuracy without using Kalman filter
|
Gesture name |
|
|
|
|
|
|
Fist |
120 |
115 |
3 |
2 |
95.83 |
|
Two |
120 |
115 |
4 |
1 |
95.83 |
|
Five |
120 |
117 |
3 |
0 |
97.50 |
|
Fist(KF) |
120 |
118 |
0 |
2 |
98.33 |
|
Two(KF) |
120 |
119 |
0 |
1 |
99.16 |
|
Five(KF) |
120 |
119 |
1 |
0 |
99.16 |
5. Conclusion
In this work, we developed a monocular camera-based hand gesture recognition system assisted by the human posture information. To improve the accuracy of this system, a user's wrist joint coordinates were calibrated using a Kalman filter. The system can detect the hands using the joint information in cases when illumination or the background is not kept constant. A user and a computer can interact efficiently since our system incorporates additional information to recognize hand gestures. However, it has a high dependency on the PoseNet. Furthermore, the processing speed is slow because the architecture of the ResNet-101 model is deep and take plenty of time for training. Future work will include the study on human pose estimation methods through deep learning to quickly recognize the hand gestures.
Acknowledgment
This research was supported by the Korean MSIT (Ministry of Science and ICT), under the National Program for Excellence in SW (2015-0-00912), supervised by the IITP (Institute for Information & communications Technology Promotion). This research was also supported by Development project of leading technology for future vehicle of the business of Daegu metropolitan city (No. 20171105).
References
[1] F. Karray, M.Alemzadeh, J. A. Saleh, M. N. Arab, “Human-Computer Interaction: Overview on State of the Art”, International Journal on Smart Sensing and Intelligent Systems, Vol. 1(1), 2008, pp. 137-159.
[2] A. Haria, A. Subramanian, N. Asokkumar, S. Poddarm, J. S. Nayak, “Hand Gesture Recognition for Human Computer Interaction”, Procedia Computer Science, Vol 115, 2017, pp. 367-374.
[3] P. Xu, “Real-time Hand Gesture Recognition and Human-Computer Interaction System”, arXiv preprint arXiv: 1704.07296, 2017.
[4] O.K. Oyedotun, A. Khashman, “Deep learning in vision-based static hand gesture recognition”, in Neural Computing and Applications, 2016, pp. 1–11.
[5] G. Papandreou, T. Zhu, L. -C. Chen, S. Gidaris, J. Tompson, and K. Murphy, "PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model", Technical report, arXiv: 1803.08225, 2018.